MySQL Query Browser
Aufgabe: Es soll eine Datentabelle mit den Namen und Adressen der Schülerinnen und Schüler der Gruppe 4a des aktuellen Jahrgangs ausgegeben werden.
Die nachfolgenden Bezeichnung und Zahlen gehören zu einer ganz bestimmten Datenbank und können deshalb mit den Daten anderer Datenbanken nicht übereinstimmen!
Um die Datentabelle erzeugen zu können, müssen zunächst einige Informationen aus der Datenbank ausgelesen werden.
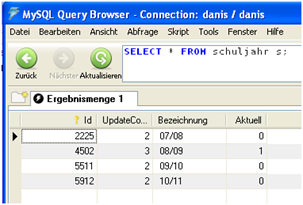
- Die Schuljahre stehen in der Tabelle „schuljahr“. Die Abfrage select * from schuljahr liefert das nebenstehende Ergebnis.
Das aktuelle Schuljahr ist „08/09“ mit der Id=4502.
Solche Ids (Identifikatiosnummern) hat in relationalen Datenbanken fast jede Datenzeile. Man benutzt sie für Abfragen und für das Verknüpfen von zusammengehörende Datenzeilen.
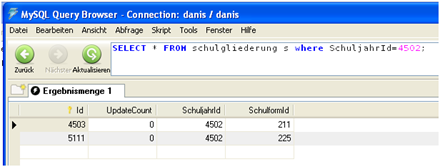
Die Ids werden automatisch von der Datenbank vergeben und haben bis auf ihre Eindeutigkeit keine weitere Bedeutung. - Welche Schulgliederungen in einem bestimmten Schuljahr existieren, steht in der Tabelle „schulgliederungen“. Die Abfrage select * from schulgliederungen where SchuljahrId=4502 liefert zwei Ergebnisse mit den SchulformIds 211 und 225. Die dazugehörenden SchulgliederungIds sind 4503 und 5111.
Will man nun wissen, welche Schulformen zu den Ids 211 oder 225 gehören, findet man die Antworten in der Tabelle „schulform“. Die Abfrage select * from schulform where Id=211 or Id=225 liefert die Ergbnisse:
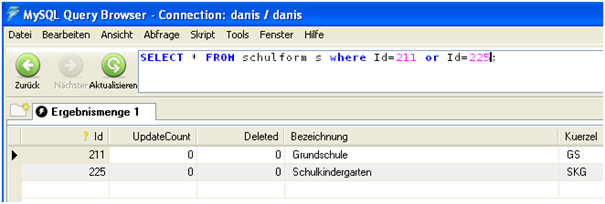
Die uns interessierende Gruppe 4a in dem aktuellen Schuljahres 08/09 (Id=4502) gehört also zu der Grundschule mit der SchulformId=211 und der SchulgliederungId=4503.
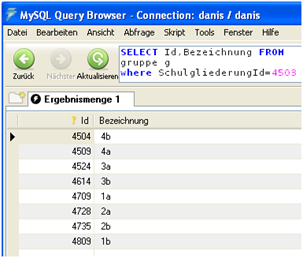
Die Id der interessierenden Gruppe 4a kann man der Tabelle „gruppe“ entnehmen. Die Abfrage select Id,Bezeichnung from gruppe where SchulgliederungId=4503 liefert die Id=4509.
TIPP: Der MySQLBrowser erlaubt auch strukturierte Eingaben, die das Lesen der Abfragen sehr erleichtern.
- In der Tabelle „schueler“ speichert DaNiS alle Schüler allerdings nur mit den Daten, die jahrgangsunabhängig sind. Ebenso sind in dieser Tabelle keine Namen und keine Adressen gespeichert.
Die Abfrage select * from schueler liefert in der vorliegenden Datenbank 345 Datensätze. Das ist die Zahl aller Schüler, die aktuell in dieser Datenbank gespeichert sind.
Das können Schüler des aktuellen Schuljahres, aber ebenso Schüler der vorhergehenden Schuljahre oder des folgenden Schuljahres sein, falls es solch ein Schuljahr schon gibt. Es muss also herausgefunden werden, welche dieser 345 Schüler gehen in die 4a des aktuellen Jahrganges.
Die richtige Aufteilung der Schülerdaten auf die einzelnen Gruppen steht in der Tabelle „jahrgangsdaten“.
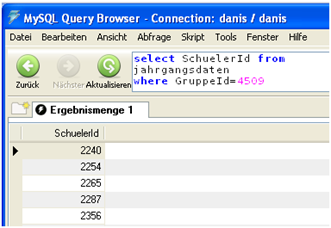
Die Abfrage select SchuelerId from jahrgangsdaten where GruppeId=4509 liefert ein Ergebnis mit 26 Datensätzen. So viele SchülerInnen hat die 4a tatsächlich.
In der Tabelle „jahrgangsdaten“ stehen aber ausschließlich jahrgangsabhängige Daten wie Gremienzugehörigkeiten, Lehrmittelausleihe usw., deswegen reicht es hier, sich nur die SchuelerId ausgeben zu lassen.
Die Namen aller Personen (Schüler, Lehrer, Verantwortliche) stehen in der Tabelle „person“.
Die bisherigen Abfragen dienten „nur“ dazu, eine Liste der SchülerIds zu erhalten, die Mitglied der Gruppe 4a in dem aktuellen Jahrgang sind.
Jetzt kann man dabei gehen diese SchülerId mit ihren Namen und Adressen zu verknüpfen. Für dieses Verknüpfen gibt es mehrere MySQL-Befehle, die immer die Befehlssequenz „join“ beinhalten. Meistens wird ein „left join“ angewandt.
Der Befehl
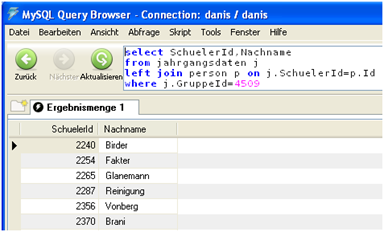
select SchuelerId,Nachname from jahrgangsdaten j left join person p on .SchuelerId=p.Id where j.GruppeId=4509
verknüpft die SchuelerId aus der Tabelle „jahrgangsdaten j“ mit der Id aus der Tabelle „person p“ und liefert als Ergebnis die SchulerId und den Nachnamen aller Schüler die der Gruppe 4a (Id=4509) angehören.
Die einzelnen Buchstaben j und p sind so genannte Aliase, die man sehr gut nutzen kann, um die einzelnen Daten von einander zu unterschieden. So beschreibt der Ausdruck p.Id die Id aus der Tabelle „person“ und j.Id wäre die Id aus der Tabelle „jahrgangsdaten“. Wenn in den miteinander verknüpften Tabellen gleich lautende Felder existieren, dann erwartet MySQL solch eine Unterscheidung.
Wenn zwei Tabellen miteinander verknüpft sind, dann kann man sich alle Felder dieser beiden Tabellen ausgeben lassen. Hierfür könnte man wieder den Stern * als Joker (select * from …) nutzen, was aber sehr schnell bei mehreren miteinander verknüpften Tabellen zu extrem vielen Felder führen würde. Deshalb sollte man, so lange es machbar ist, die Felder, die ausgegeben werden sollen, einzeln in die Abfrage schreiben.
Es sollen jetzt noch der Vorname und das Geschlecht ausgegeben werden. Deshalb muss die Ausgabeliste entsprechend erweitert werden.
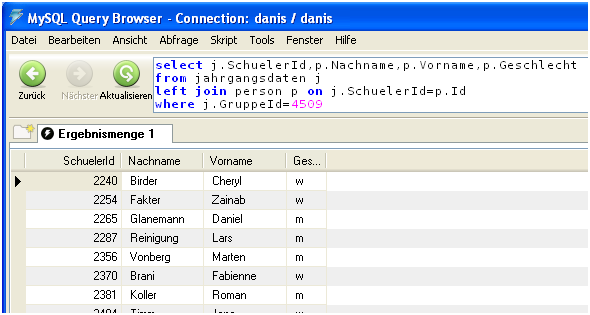
Für die Aufgabenerfüllung fehlen jetzt noch Adressen, die natürlich nicht in der Tabelle „person“ stehen. Die Adressen stehen in der Tabelle „adresse“, die wiederum über die SchuelerId mit dem obigen Ergebnis verknüpft wird.
Es muss also ein weiterer join-Befehl eingefügt werden.
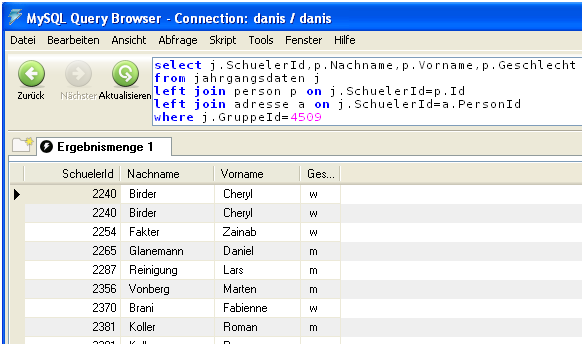
Dieser join-Befehl verknüpft das bisherige Ergebnis mit der Tabelle „adresse“. Er führt noch nicht dazu, dass jetzt die Adressen mit angezeigt werden. Die weiteren zusätzlich Felder müssen erst noch in die Ausgabeliste hinter dem select-Befehl geschrieben werden.
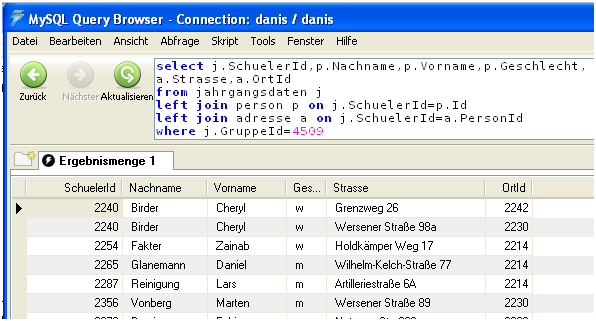
In der Tabelle „adresse“ steht (natürlich) keine PLZ und kein Ortsname, denn dann würde ja hinter zig Straßen immer der selbe Ortsname stehen. Stattdessen wird in „adressen“ nur eine OrtId gespeichert und die eigentlichen Ortsnamen und Postleitzahlen erhält man wieder über eine weitere Verknüpfung mit der Tabelle „ort“.
Das nächste Bild zeigt die komplette Verknüpfung und die erweiterte Ausgabeliste:
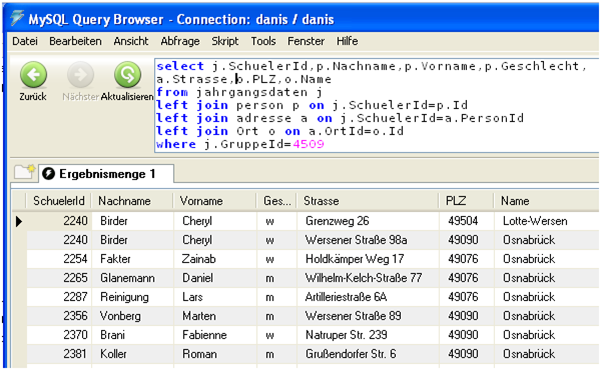
Die Verknüpfung läuft über die OrtId der Tabelle „adresse“. Dies funktioniert auch, wenn man die OrtId nicht mit ausgeben lässt. Deshalb wurde das Feld a.OrtId in dem obigen Bild wieder aus der Ausgabeliste entfernt. Es ist überflüssig und wird jetzt nur noch für die Verknüpfung genutzt.
Möchte man eine geordnete und sortierte Listenausgabe erhalten, dann kann man hinter dem where-Befehl noch einen order by-Befehl schreiben, der dann dafür sorgt, dass die Ausgabe sortiert wird.
Dieses Zusammensammeln der gewünschten Daten in der oben beschriebenen Form ist längst nicht so mühselig, wie man es beim ersten Kennenlernen empfindet. Diese Gedankengänge, wo bekomme ich auf welchem Weg die Daten her, die ich für meinen Bericht brauche, werden ziemlich schnell Routine.
Ferner muss man ja gar nicht für jeden neuen Berricht immer wieder von vorne anfangen, sondern kann sehr häufig auf schon existierenden Abfragen zurückgreifen. Schließlich stellt DaNiS die Schüler-Stammdaten schon in einer virtuellen Tabelle fix und fertig zur Verfügung. Diesen Daten stehen mit der Abfrage select * from danis für eine Berichtserstellung zur Verfügung.